
Docker: High Availability di Docker Swarm

 Pada kali ini saya akan menulis tentang bagaimana implementasi High Availability pada docker swarm. sebelumnya saya telah menulis konfigurasi dan penggunaan dasar menggunakan docker swarm temen temen bisa baca artikel sebelumnya mengenai dasar dasar penggunaan di docker swarm.
Pada kali ini saya akan menulis tentang bagaimana implementasi High Availability pada docker swarm. sebelumnya saya telah menulis konfigurasi dan penggunaan dasar menggunakan docker swarm temen temen bisa baca artikel sebelumnya mengenai dasar dasar penggunaan di docker swarm.
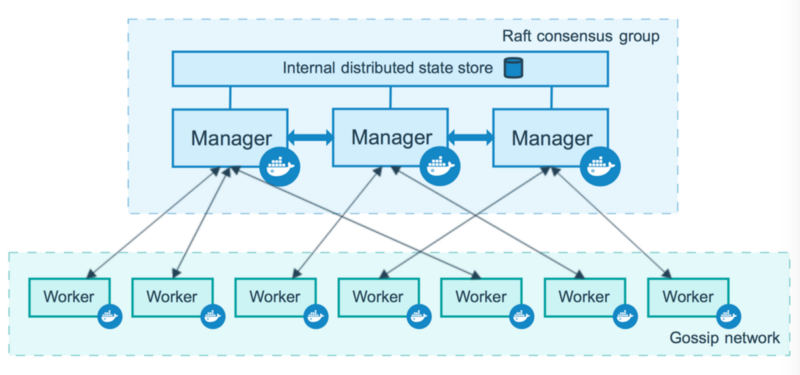
Docker Swarm memiliki dua jenis node dalam klasternya yaitu node manager dan node worker. singkatnya node manager yang berperan mengatur kebijakan di klaster dan memberi perintah, sedangkan worker adalah pekerjanya yang nanti akan mengeksekusi kontainer. Untuk High Availability atau ketersediaan tinggi setidaknya kita membutuhkan 3 manager.
- 3 manager, batas maksimum node manager mati adalah 1.
- 5 manager, batas maksimum node manager mati adalah 2.
- 7 manager, batas maksimum node manager mati adalah 3.
rumusnya adalah (N-1)/2 , misalnya 3 manager berarti (3–1)/2 = 1. Artinya batas node manager mati jika ada 3 manager adalah 1 manager. Dari dokumentasi website docker nya merekomendasikan menggunakan kelipatan hitungan ganjil untuk node manager dan juga maksimal node manager adalah 7. disini total server yang akan saya gunakan untuk simulasi high availability (HA) adalah 5 Server. 3 buah server sebagai node manager dan 2 buah nya lagi menjadi node worker. dibawah ini adalah gambaran klaster swarm beserta ip tiap server
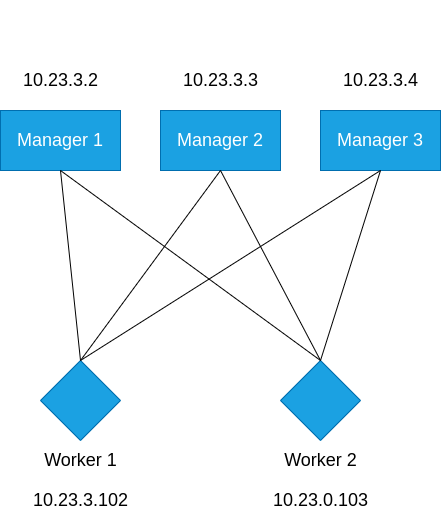
Pertama, inisialisasi server manager 1 agar menjadi leader
1
$ docker swarm init --advertise-addr 10.23.3.2
setelah perintah diatas dieksekusi maka akan muncul output seperti dibawah.

lakukan join cluster dengan menjalankan perintah yang ditandai pada gambar di server yang ingin join ke cluster sebagai worker. untuk server yang ingin join sebagai manager bisa gunakan perintah “docker swarm join-token manager” setelah itu akan muncul output nya yang bisa digunakan untuk join sebagai manager.
selanjutnya adalah tahap pengujian High Availability dimana kita akan menjalankan service kemudian melakukan pengujian dengan mematikan beberapa node manager. dibawah ini terlihat telah ada 5 node, untuk best practice sebaiknya untuk deploy service hanya di node worker saja, jadi biarlah node manager bertugas menerima request dari klien dan meneruskan nya ke worker serta mengatur aktivitas di klaster.

1
$ docker service create --name webserver --replicas=6 nginx:alpine
maksud perintah diatas adalah kita membuat service nginx dengan replica 6 atau 6 kontainer yang akan disebar ke node node di klaster. kemudian kita akan coba matikan satu manager yaitu server manager 3 misalkan

lalu matikan manager 2 juga

dan cek node ls status dari klaster atau node node dalam klaster

jika hanya tersisa satu manager akan muncul output seperti dibawah ini dimana kita tidak bisa lagi manage cluster, dikarenakan sebagaimana penjelesan diawal bahwa 3 manager hanya memiliki toleransi kesalahan jika satu manager saja yang mati.

untuk akses ke service nya sendiri itu masih bisa walau tersisa satu manager, tetapi kita tidak bisa lagi membuat service dan mengatur aktivitas lainnya di dalam klaster. ketika kita coba akses curl dari server manager 1 itu sudah otomatis sifatnya load balance
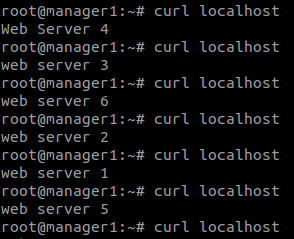
jadi saya sudah mengganti konten tiap server dari keenam replika yang sudah dibuat tadi, tiap kontainer yang tersebar ke node konten nya saya ganti untuk pengujian load balance. nah tetapi, ketika kita mengakses konten atau service nya dari browser maka sifatnya nya adalah yang dimana request dari klien akan ditandai dari request pertama, jika request pertama mengarah ke webserver A maka requets selanjutnya akan diarahkan lagi ke A.
Akhir
Good Luck Selamat Mencoba 😁, jika ada pertanyaan temen temen bisa tanyakan dan diskusikan di kolom komentar yaaaa